kgp.py employs several tricks which may or may not be useful to you in your XML processing. The first one takes advantage of the consistent structure of the input documents to build a cache of nodes.
A grammar file defines a series of ref elements. Each ref contains one or more p elements, which can contain lots of different things, including xrefs. Whenever we encounter an xref, we look for a corresponding ref element with the same id attribute, and choose one of the ref element’s children and parse it. (We’ll see how this random choice is made in the next section.)
This is how we build up our grammar: define ref elements for the smallest pieces, then define ref elements which "include" the first ref elements by using xref, and so forth. Then we parse the "largest" reference and follow each xref, and eventually output real text. The text we output depends on the (random) decisions we make each time we fill in an xref, so the output is different each time.
This is all very flexible, but there is one downside: performance. When we find an xref and need to find the corresponding ref element, we have a problem. The xref has an id attribute, and we want to find the ref element that has that same id attribute, but there is no easy way to do that. The slow way to do it would be to get the entire list of ref elements each time, then manually loop through and look at each id attribute. The fast way is to do that once and build a cache, in the form of a dictionary.
Example 5.37. loadGrammar
def loadGrammar(self, grammar):
self.grammar = self._load(grammar)
self.refs = {} 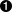 for ref in self.grammar.getElementsByTagName("ref"):
for ref in self.grammar.getElementsByTagName("ref"): 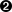 self.refs[ref.attributes["id"].value] = ref
self.refs[ref.attributes["id"].value] = ref 

| Start by creating an empty dictionary, self.refs. | |
| As we saw in Searching for elements, getElementsByTagName returns a list of all the elements of a particular name. We easily can get a list of all the ref elements, then simply loop through that list. | |
| As we saw in Accessing element attributes, we can access individual attributes of an element by name, using standard dictionary syntax. So the keys of our self.refs dictionary will be the values of the id attribute of each ref element. | |
| The values of our self.refs dictionary will be the ref elements themselves. As we saw in Parsing XML, each element, each node, each comment, each piece of text in a parsed XML document is an object. |
Once we build this cache, whenever we come across an xref and need to find the ref element with the same id attribute, we can simply look it up in self.refs.
Example 5.38. Using our ref element cache
def do_xref(self, node):
id = node.attributes["id"].value
self.parse(self.randomChildElement(self.refs[id]))We’ll explore the randomChildElement function in the next section.